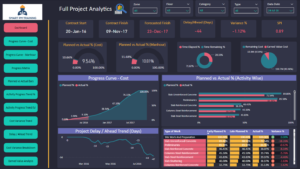
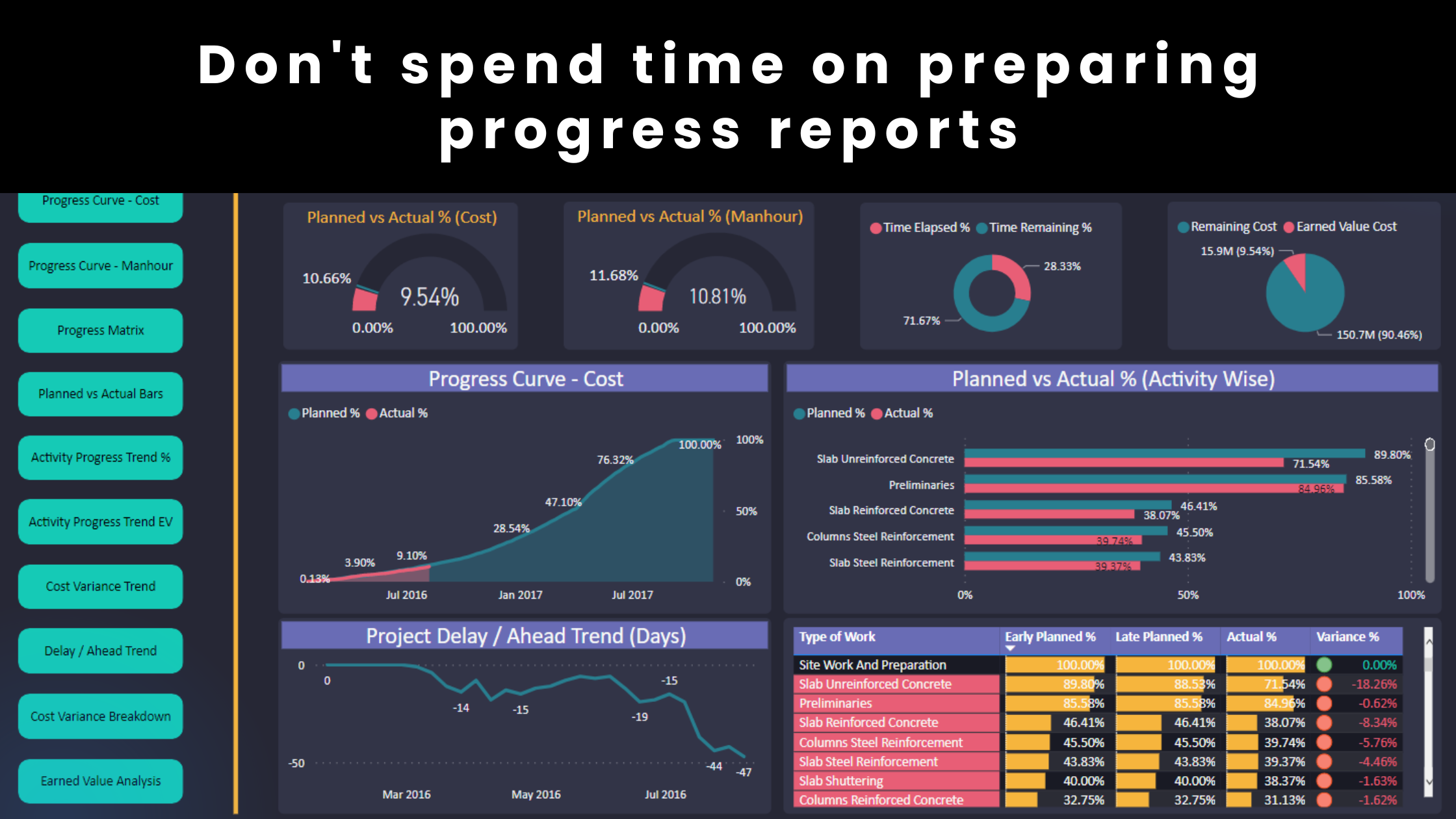
When an AI model recommends an action to prevent cost overruns in a project, it does not actually know the answer. Instead, it predicts an outcome based on data. Specifically, it relies on three types of data:
-
Training data
-
Input data
-
Feedback data
Understanding the Three Types of Data
Training data is what was originally used to create the model. This can include cost baselines from your current project and the causes of cost overruns from previous projects.
Input data is the information you provide for your current project when you use the AI model. For example, if you want insights into cost control, you need to combine inputs such as staff salaries (what statisticians call independent variables) with cost overruns as an output (the dependent variable).
If you hire new site engineers, you can already identify whether cost overruns occurred using an Excel sheet without any AI. This is a simple cause-and-effect relationship. In such cases, an AI model may not be necessary. A basic regression analysis might be sufficient, where you identify known causes of overruns and relate them to the fact that a project finishes over budget.
Deep Learning Goes Further
Deep learning takes this one step further. Instead of only analyzing relationships you already expect, it generates insights about combinations you may not have considered. For example, the model might recommend hiring two site engineers with a minimum of five years of local experience rather than hiring three site engineers with less local experience. The latter option may be associated with higher risks of quality defects and longer execution time, which ultimately leads to higher costs. In this scenario, experience becomes a critical factor.
Moreover, there are both fixed and variable costs. For example, expenses such as residence visas, work permits, and insurance tend to remain relatively stable for engineers with, say, 1–8 years of experience, whereas salary represents a variable cost that changes significantly. An AI model can optimize decisions by accounting for these parameters.
You decide whether to follow the AI recommendation, then observe the outcome. The result, whether positive or negative, becomes feedback data, which the model can learn from to improve future predictions. You can imagine the number of possible combinations across head office, design, procurement, and other functions that collectively influence project success.
Accuracy Improves Over Time
Neither regression analysis nor deep learning provides answers that are 100% accurate. A regression model might start with an accuracy of around 80%, while an AI model may initially be closer to 70%. However, with sufficient data and feedback, deep learning models can improve significantly, sometimes reaching accuracy levels as high as 97%.
The key difference is this:
-
Regression analysis improves linearly
-
Deep learning improves exponentially
Timing Matters: Before vs. After the Decision
AI models generate insights based on the input data you provide. Therefore, timing is critical. In the hiring example, it is important to input candidate data before making a final decision. You may shortlist candidates, but the data should be fed into the AI model before you receive approval to hire.
If AI is only used after decisions are made, it becomes redundant. Its real value lies in supporting decisions before action is taken, not after the fact.
Why Is It Called “Intelligence”?
Humans can only identify a limited number of cause-and-effect combinations. This is because our short-term memory is limited, and our analytical processing is relatively slow. AI models, on the other hand, can process thousands of combinations quickly and effectively. Interestingly, humans also operate primarily on predictions.
Imagine you have a meeting at 10:00 a.m. in a location you’ve never visited before. You start driving at 9:30 a.m. based on a prediction. However, you spend an extra 20 minutes searching for parking. Your brain records this as feedback data and adjusts your prediction next time by accounting for parking delays on weekdays. Later, you discover that parking is even harder to find on weekends. This becomes another variable in your prediction model. This is exactly how feedback works.
That’s also why we are encouraged to try new experiences rather than remain in our comfort zones. New experiences allow us to accumulate more data and feedback, leading to better predictions and better decisions across different areas of life. There is no such thing as failure – only feedback data.
This is also why adults are generally wiser than seven-year-old children. Adults have accumulated more data and feedback, enabling them to make decisions with more accurate outcomes on average. If you would like to learn more about AI predictions, I highly recommend this book: “Prediction Machines: The Simple Economics of Artificial Intelligence by Ajay Agrawal, Joshua Gans and Avi Goldfarb”
AI adoption becomes easy and abundant
When service becomes cheap and abundant, adoption increases, and the world changes. In the past, communication across distances involved high friction. You had to physically visit a post office to send a letter. International calls were expensive, so communication required a strong justification. Messages were short and precise. Today, with the internet, you can message anyone instantly. Emails can be sent and read all day without worrying about cost or length. The associated cost has fallen close to zero. The same principle now applies to AI.
There are tools available that allow us to build AI models quickly and cheaply. Companies like Microsoft and Google offer end-to-end solutions that enable organizations to migrate data to the cloud, build data architectures, and develop AI models efficiently.
This abundance is what makes widespread adoption and meaningful impact possible.